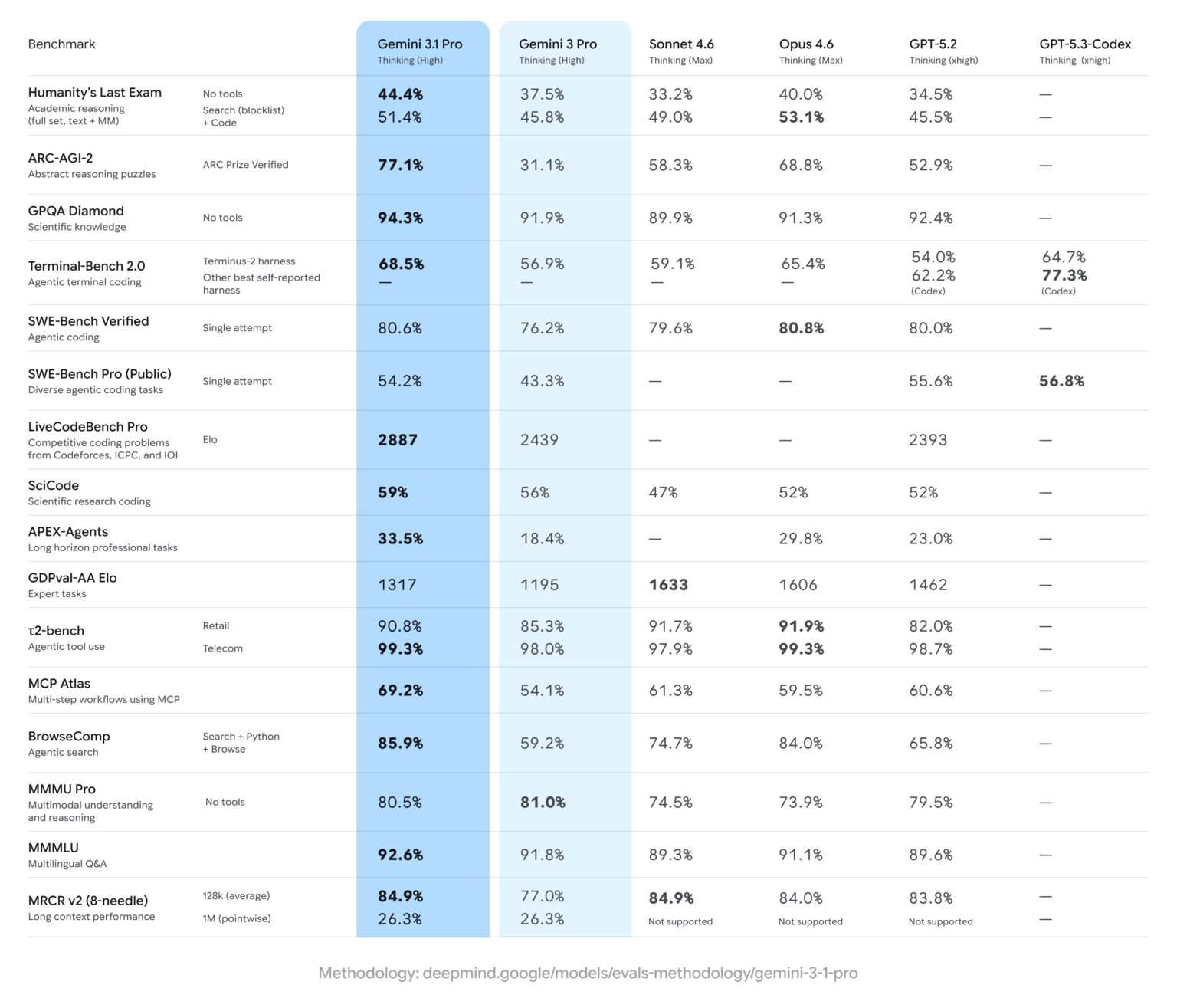
As is typical with major model updates, Google highlighted benchmark gains. In Humanity’s Last Exam, which evaluates advanced domain-specific knowledge, Gemini 3.1 Pro scored 44.4%, up from Gemini 3 Pro’s 37.5% and ahead of OpenAI’s GPT 5.2 at 34.5%. The company also emphasized progress on ARC-AGI-2, a benchmark featuring novel logic problems designed to resist direct training. Gemini 3 previously scored 31.1% on that test, but 3.1 Pro more than doubled that performance to 77.1%.
Still, Gemini 3.1 Pro does not top every leaderboard. On the Arena leaderboard (formerly LM Arena), which ranks models based on user preference voting, Anthropic’s Claude Opus 4.6 leads Gemini by four points in text performance at 1504. In coding evaluations, Opus 4.6, Opus 4.5 and GPT 5.2 High also rank ahead of Gemini 3.1 Pro.
Beyond benchmarks, Google demonstrated improvements in graphics and simulation generation, showing more refined SVG outputs in curated examples. Developers building agent-style workflows may also see gains: Gemini 3.1 Pro nearly doubled its score on the APEX-Agents benchmark, which measures agentic task performance.
For users, the practical impact may depend on use case. Those asking abstract or nuanced questions could notice more detailed responses compared with Gemini 3.0, while developers working with agent-based systems may benefit most from the upgrade.
The rapid iteration underscores how frequently major AI labs are updating flagship models as competition intensifies. If past patterns hold, Google is likely to release a 3.1 update for its faster, lower-cost Flash variant in the near future.
This analysis is based on reporting from Ars Technica.
Image courtesy of Google.
This article was generated with AI assistance and reviewed for accuracy and quality.
