Unlike earlier embedding systems focused primarily on text, Gemini Embedding 2 supports several types of media. The model can process up to 8,192 input tokens of text, analyze up to six images per request in PNG or JPEG formats, and handle video clips up to 120 seconds long in MP4 or MOV formats. It can also embed audio without requiring transcription and directly process PDF documents up to six pages in length.
Google said the model can also interpret interleaved inputs, allowing developers to combine modalities in a single request, such as submitting both an image and descriptive text together. The goal is to capture relationships between different types of information within a unified representation.
“Gemini Embedding 2 maps text, images, videos, audio and documents into a single, unified embedding space, and captures semantic intent across over 100 languages,” Google said in a blog post announcing the release.
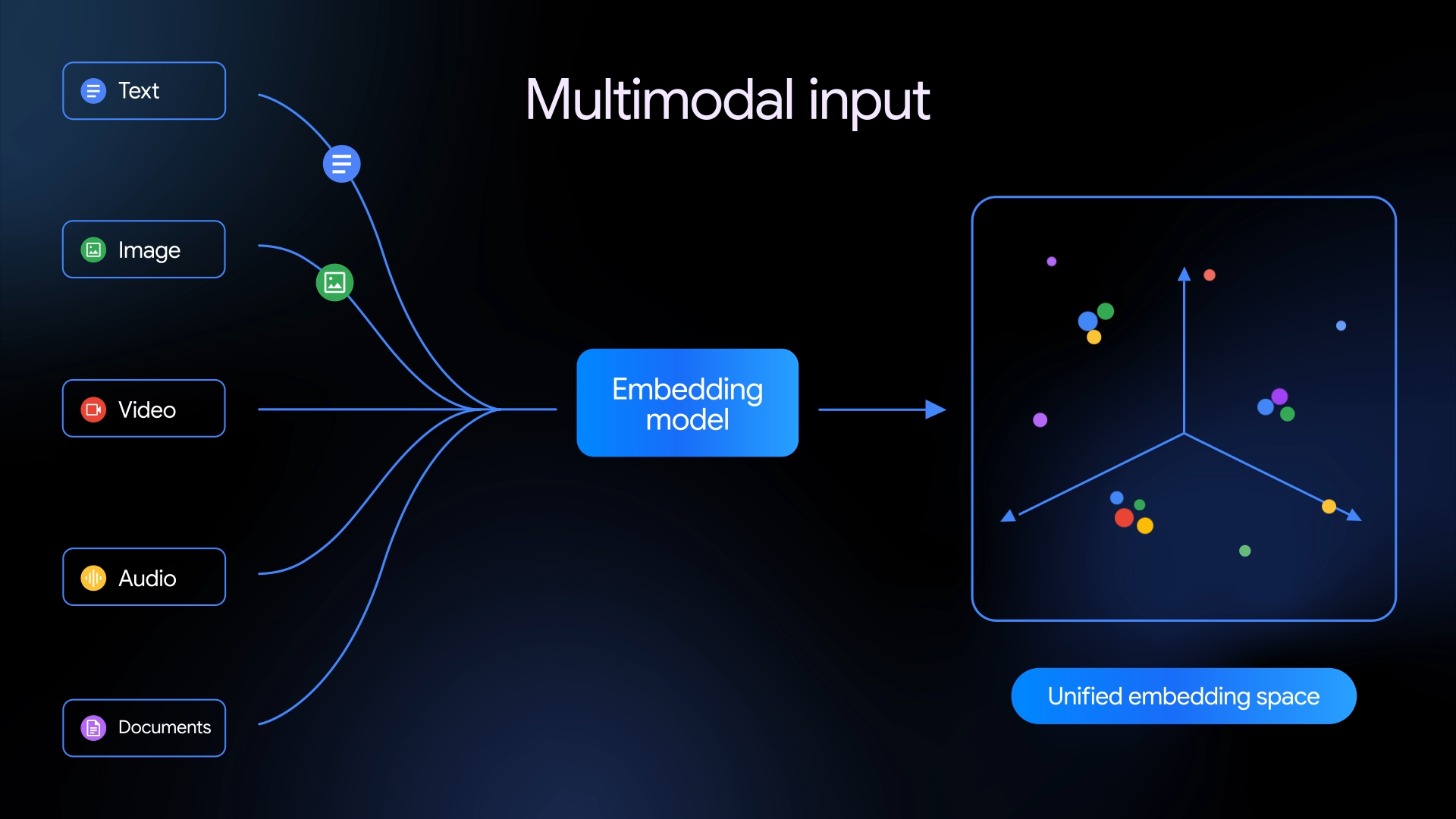
The company added that the model builds on Gemini’s broader multimodal capabilities. “Gemini Embedding 2 doesn’t just improve on legacy models,” Google said. “It establishes a new performance standard for multimodal depth, introducing strong speech capabilities and outperforming leading models in text, image, and video tasks.”
Gemini Embedding 2 includes a technique called Matryoshka Representation Learning, which allows developers to adjust the size of the output embedding. The default output dimension is 3,072, but it can be scaled down to 1,536 or 768 dimensions depending on performance and storage requirements.
Google said embeddings produced by the system are designed to support large-scale information retrieval and organization. The company noted that some early partners are already applying the model to analyze complex datasets containing multiple types of media.
Developers can access the model through Google’s AI platforms or integrate it with tools such as LangChain, LlamaIndex, Haystack, Weaviate, Qdrant, ChromaDB and Vector Search.
This analysis is based on reporting from Google.
Images courtesy of Google.
This article was generated with AI assistance and reviewed for accuracy and quality.
