DiffusionGemma is aimed at developers working on interactive workflows where response speed is critical. Google highlighted use cases including in-line editing, rapid iteration, code infilling, mathematical graphs, and amino acid sequence generation. The company said the model’s architecture allows 256 tokens to be generated in parallel, giving each token visibility into the broader context of the text being created.
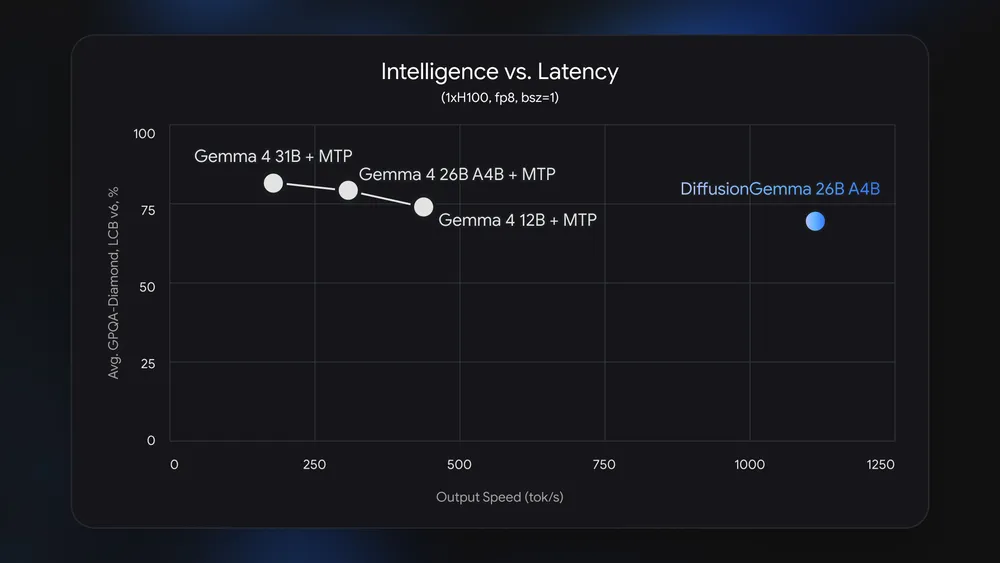
The model operates as a 26B Mixture of Experts system but activates only 3.8 billion parameters during inference. According to Google, that enables it to run within 18GB of VRAM when quantized, making it accessible on high-end consumer hardware.
Another key feature is the model’s ability to iteratively refine its own output. Rather than generating text in a single pass, DiffusionGemma repeatedly evaluates and improves an entire block of text, allowing it to correct errors during the generation process.
Google emphasized that the model remains experimental and is not intended to replace standard Gemma 4 deployments. The company said output quality remains lower than its autoregressive counterparts and recommends Gemma 4 for applications where generation quality is the primary consideration.
The release also serves as a practical test of diffusion-based text generation, an area that has attracted research interest for years but has been difficult to scale effectively. Google argues that diffusion changes how AI workloads utilize hardware by processing larger chunks of text simultaneously instead of advancing word by word.
The process resembles image-generation diffusion models. DiffusionGemma begins with a sequence of placeholder tokens, then performs multiple refinement passes before converging on a final output. Because the model evaluates larger sections of text at once, Google says it can handle certain non-linear generation tasks more effectively than traditional language models.
Google pointed to fine-tuning as a way to improve performance for specialized workloads. In one example, AI startup Unsloth fine-tuned DiffusionGemma to solve Sudoku puzzles, a task Google said benefits from the model’s bi-directional attention mechanism.
The company is making the model available through Hugging Face and supporting deployment across a range of tools, including MLX, vLLM, Hugging Face Transformers, Unsloth, and NVIDIA NeMo. Support for llama.cpp is expected to arrive later. Google also said it worked with NVIDIA on optimizations for both consumer and enterprise hardware platforms, including GeForce RTX GPUs and NVIDIA’s Hopper and Blackwell systems.
While the model’s performance advantages are most apparent in local and low-concurrency environments, Google said the benefits become less pronounced in high-volume cloud deployments where traditional autoregressive models can more efficiently utilize hardware resources through batching.
This analysis is based on reporting from Google.
Images courtesy of Google.
This article was generated with AI assistance and reviewed for accuracy and quality.
