The upgrade is now live for Google AI Ultra subscribers in the Gemini app, with API access available to researchers through an early access program.
Deep Think is designed for scenarios where extended reasoning matters more than speed — multi-step mathematics, scientific modeling, complex coding challenges, and engineering problem-solving that require sustained logical chains. Rather than optimizing for fast conversational responses, the system is tuned for accuracy and depth, reflecting a broader shift in how frontier AI labs are differentiating their models.
That shift is happening against a competitive backdrop. OpenAI has pushed its o-series reasoning models as capable of “thinking” longer before responding, while Anthropic continues advancing Claude’s analytical strengths. With Deep Think, Google is clearly targeting the same enterprise and academic audiences — but now with benchmark comparisons positioned prominently at launch.
Alongside the Deep Think upgrade, Google also introduced Aletheia, a math-focused AI agent built to autonomously solve open problems and verify proofs. The company says Aletheia hits new highs across domain benchmarks and is designed specifically for formal mathematical reasoning tasks. Its debut suggests Google is building a layered approach to advanced reasoning — pairing a general-purpose deep reasoning mode with specialized agents focused on narrow, high-precision domains.
The emphasis on benchmarks marks a notable evolution in messaging. As general-purpose chatbot capabilities become more standardized across providers, competition is moving up the complexity curve. Academic reasoning tests, Olympiad performance, and competitive programming scores are increasingly being used to demonstrate differentiation in high-stakes professional contexts.
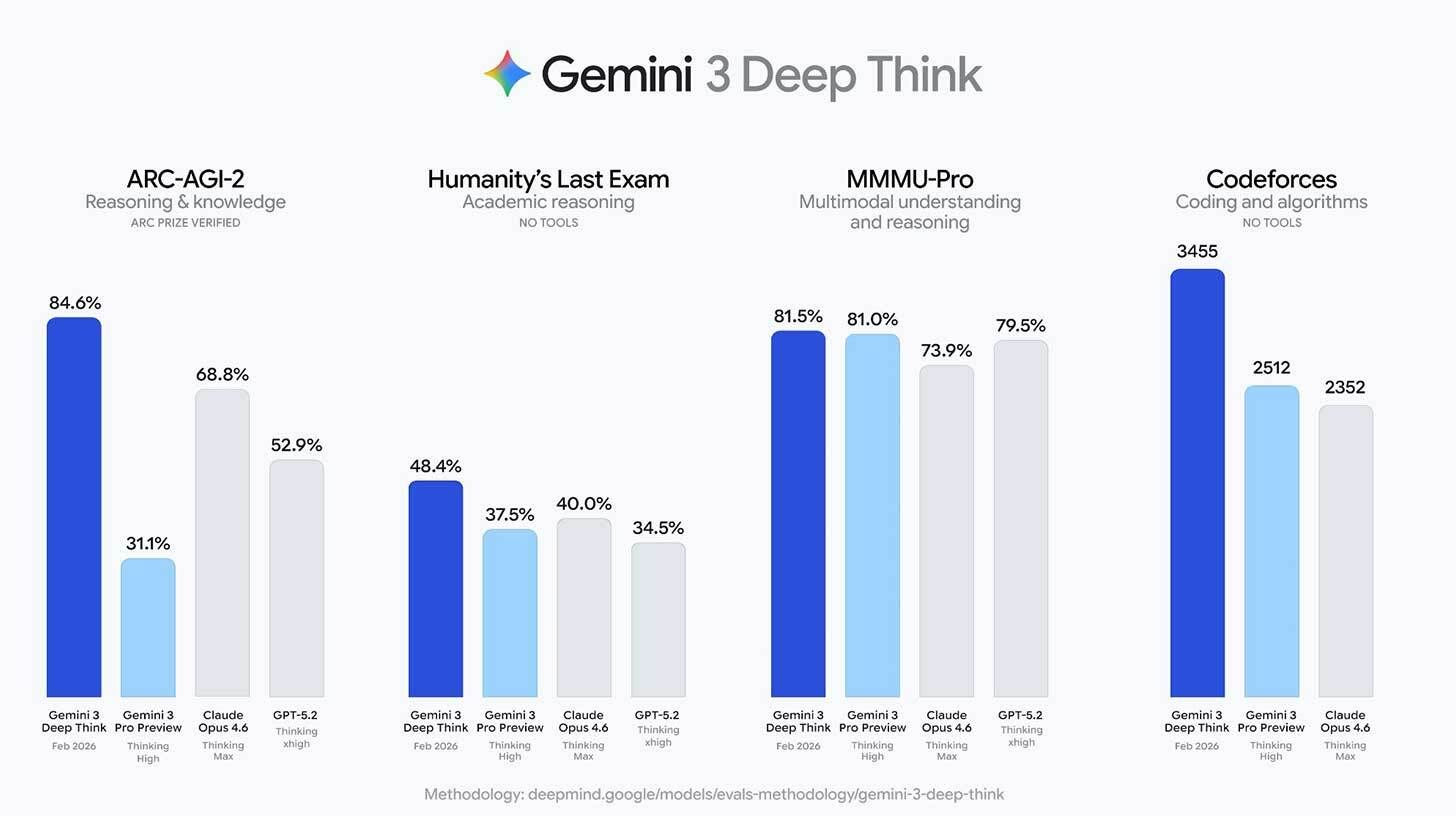
For enterprise and research users, the calculus is changing. It’s no longer just about which model writes faster or summarizes better. Organizations evaluating AI tools for scientific research, financial modeling, or advanced engineering need systems that can handle multi-step reasoning with consistency. By highlighting ARC-AGI-2, Humanity’s Last Exam, and Codeforces results, Google is signaling that Deep Think is built for that tier of work.
The real test will be adoption. Benchmark leadership can signal capability, but research institutions and engineering teams tend to prioritize reliability and reproducibility over headline numbers. By limiting early access to AI Ultra subscribers and controlled API programs, Google appears to be focusing first on high-value users who require deeper analytical performance.
With the Deep Think upgrade and the introduction of Aletheia, Google has made clear that it intends to compete aggressively in the upper tier of AI reasoning — where extended analysis, mathematical rigor, and structured problem-solving matter more than conversational speed.
This analysis is based on reporting from techbuzz.
Images courtesy of Google.
This article was generated with AI assistance and reviewed for accuracy and quality.
